
In the previous post on the Azure AI Language, you saw how to provision and configure an instance of the Azure AI Language service and a simple example of using sentiment analysis and key phrase extraction. In this post we will look as another feature of the Language service, Named Entity Recognition or NER.
The NER feature of the Language service detects notable entities in a body of text such as people, places and organizations. For example, Satya Nadella would be an example of a person recognized by NER while Microsoft would be an example of an organization. In total, NER can recognize 14 different entity categories. A complete list can be found here.
The prerequisites for using the NER feature are the same as using the sentiment analysis feature. You need to provision an instance of the Language service and get the endpoint and keys to create a TextAnalyticsClient that you will use to communicate with the Language service. So we’ll start from there.
Using the NER feature
As I said in the previous post about the Language service, most of the “hard work” of getting a prediction from an AI model is reduced to a single line of code. The NER feature is no exception. Once you have a client, simple call the recognize_entities method and pass it of a list of strings, which will be referred to as documents. For example, let’s use this short passage about interesting things in Nashville, Tennessee. (courtesy ChatGPT)
Nashville, Tennessee, is often known as “Music City,” a title that rings true thanks to its rich history and vibrant cultural scene. While Nashville has become synonymous with country music, the city is also celebrated for its notable residents, groundbreaking music venues, and contributions to art, education, and civic life.
Nashville’s story is one of creativity, resilience, and tradition. From the legacies of Dolly Parton and Andrew Jackson to the lively scenes on Broadway Street, Nashville continues to attract visitors and inspire artists worldwide. Whether you’re a music lover, a history buff, or simply someone looking to experience a slice of Southern culture, Nashville offers a warm welcome and countless stories to uncover.
Assuming a TextAnalyticsClient instance named client, the single line of code that does the “hard work” is this.
results = client.recognize_entities(
documents=[nashville_document]
)The return value will contain one result for each document. Inside each result is a entities attribute. Each entity contains data such as the entity text, the category and a confidence_score.
entity_categories = {}
for entity in document.entities:
if entity.category not in entity_categories:
entity_categories[entity.category] = []
entity_categories[entity.category].append(
{
"text": entity.text,
"confidence_score": entity.confidence_score
}
)Here is an excerpt of the entities extracted:
{
"Location": [
{
"text": "Nashville",
"confidence_score": 1.0
},
{
"text": "Tennessee",
"confidence_score": 0.98
}
],
"PersonType": [
{
"text": "residents",
"confidence_score": 0.88
}
],
"Skill": [
{
"text": "art",
"confidence_score": 0.91
}
],
"Quantity": [
{
"text": "one",
"confidence_score": 0.8
}
],
"Person": [
{
"text": "Dolly Parton",
"confidence_score": 1.0
},
{
"text": "Andrew Jackson",
"confidence_score": 1.0
}
],
"Address": [
{
"text": "Broadway Street",
"confidence_score": 0.94
}
]
}The NER feature found entities in 6 different categories:
- Location
- PersonType
- Skill
- Quantity
- Person
- Address
This example used a generalized model. The Azure AI Service also offers a domain-specific model for health data. This models extends the entity categories with topics including anatomy, examinations and medication.
To extract entities for health data, you call the begin_analyze_healthcare_entities method of the TextAnalyticsClient. To get the results for each document, you must call the result method.
result = client.begin_analyze_healthcare_entities(
[allegriclear_study]
).result()And this is an excerpt from the entities extracted from a fictional study about a new allergy treatment called AllergiClear. (courtesy of ChatGPT)
{
"Diagnosis": [
{
"text": "Allergic rhinitis",
"confidence_score": 1.0
},
{
"text": "seasonal allergies",
"confidence_score": 1.0
}
],
"SymptomOrSign": [
{
"text": "sneezing",
"confidence_score": 1.0
},
{
"text": "congestion",
"confidence_score": 1.0
}
],
"TreatmentName": [
{
"text": "treatments",
"confidence_score": 0.61
},
{
"text": "symptom management",
"confidence_score": 0.65
}
],
"MedicationName": [
{
"text": "AllergiClear",
"confidence_score": 0.95
}
],
"Frequency": [
{
"text": "daily",
"confidence_score": 0.99
}
],
"Time": [
{
"text": "12 weeks",
"confidence_score": 0.99
},
{
"text": "end of 12 weeks",
"confidence_score": 0.92
}
]
}
The complete list of healthcare categories can be found here.
Linked Entities
The Azure AI Language service can also provides references to additional information about entities. By calling the recognized_linked_entities method of the TextAnalyticsClient you can get this additional information. It includes a data for the linked information including a url and data_source. The result also includes the text that was matched in the document for each linked entity and a confidence_score.
result = client.recognize_linked_entities([nashville_document])
for entity in result[0].entities:
link = {
"name": entity.name,
"url": entity.url,
"data source": entity.data_source,
"matches": [
{
"text": match.text,
"confidence_score":match.confidence_score
}
for match in entity.matches
]
}
print(json.dumps(link, indent=4)) Here is the linked entity data for the Nashville document.
{
"name": "Nashville, Tennessee",
"url": "https://en.wikipedia.org/wiki/Nashville,_Tennessee",
"data source": "Wikipedia",
"matches": [
{
"text": "Nashville, Tennessee",
"confidence_score": 0.56
},
{
"text": "Music City",
"confidence_score": 0.55
}
]
}
{
"name": "Dolly Parton",
"url": "https://en.wikipedia.org/wiki/Dolly_Parton",
"data source": "Wikipedia",
"matches": [
{
"text": "Dolly Parton",
"confidence_score": 0.88
}
]
}
{
"name": "Andrew Jackson",
"url": "https://en.wikipedia.org/wiki/Andrew_Jackson",
"data source": "Wikipedia",
"matches": [
{
"text": "Andrew Jackson",
"confidence_score": 0.21
}
]
}
{
"name": "Broadway (Nashville, Tennessee)",
"url": "https://en.wikipedia.org/wiki/Broadway_(Nashville,_Tennessee)",
"data source": "Wikipedia",
"matches": [
{
"text": "Broadway Street",
"confidence_score": 0.13
}
]
}
{
"name": "Culture of the Southern United States",
"url": "https://en.wikipedia.org/wiki/Culture_of_the_Southern_United_States",
"data source": "Wikipedia",
"matches": [
{
"text": "Southern culture",
"confidence_score": 0.81
}
]
}Again, this is coming from a generically trained model. If you have data specific to a domain such as a company or event that is not widely known, you can train a model to recognize entities from that data. There is no SDK for training custom NER models, but you can use the REST API or Language Studio. Training a custom NER model is outside the scope of this post. But you can try out the other features from before using Language Studio so let’s take a look at it.
Using Language Studio
If you want to use the features of the Azure AI Language Service without creating an application, you can use Language Studio. Access the Language Studio by going to https://language.cognitive.azure.com/ in your browser.
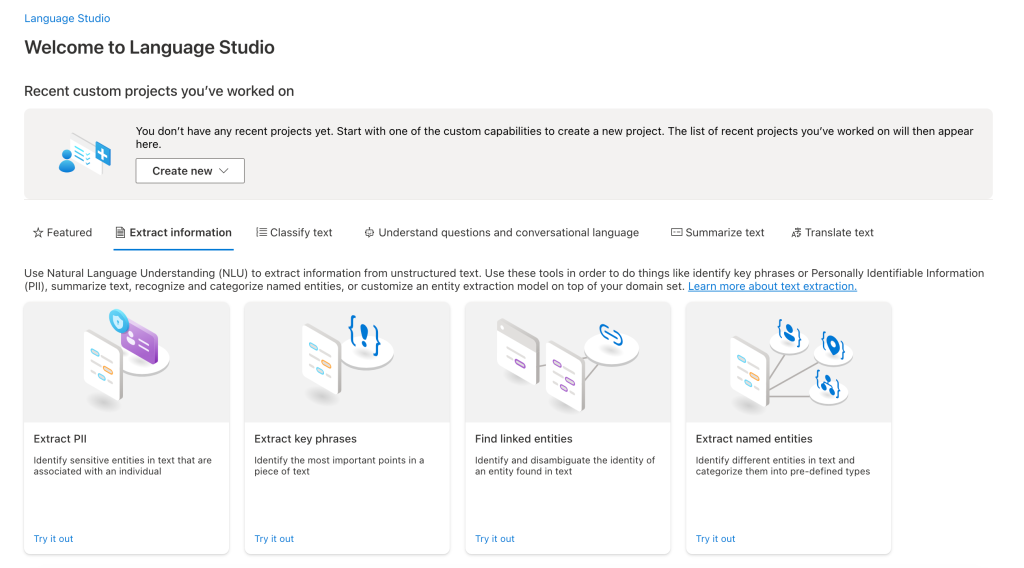
The Extract Information tab lets you use the NER and linked entity features discussed in this post, but you can also use the extract key phrases feature from the previous post. And under the Classify text tab you can find sentiment analysis. For this demo, I’ll click on the Extract named entities link.
To use named entity recognition in Azure Language Studio you’ll have to choose a model version (the most recent is selected), the language of the text to analyze, and the name of a Language service instance in your Azure subscription. In the textarea paste the text to analyze or select one of the provided examples.
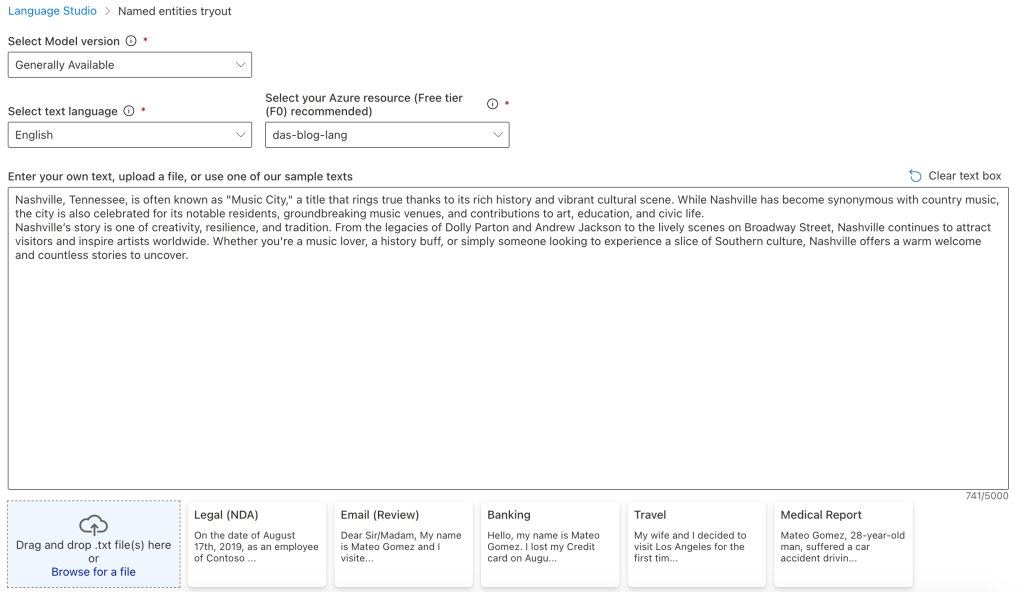
Below the examples is a checkbox. You must check the box to acknowledge that using Language Studio will consume resources from your Language Service instance. Then click the Run button to start.

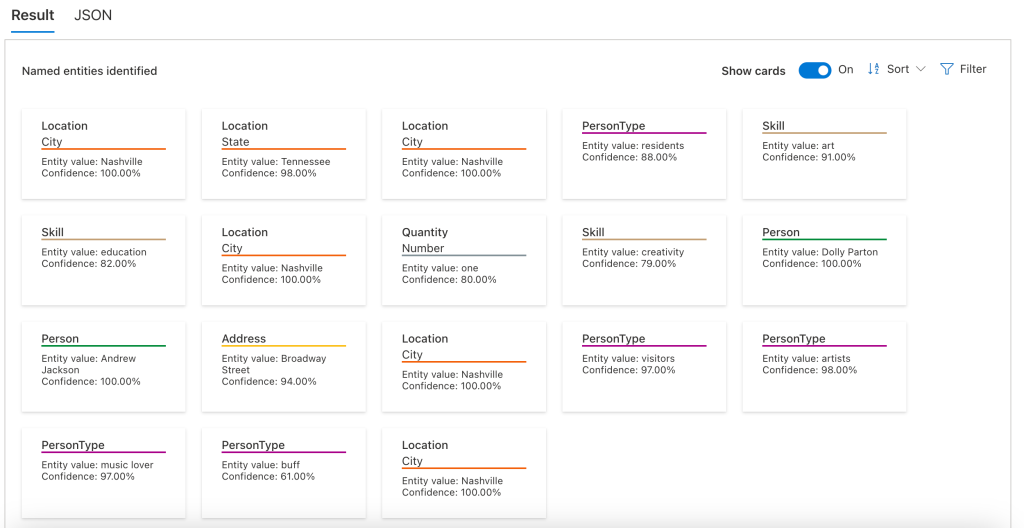
Azure Language Studio will show the results in different ways. The cards view shows a card for each extracted entity with category and subcategory at the top. Then is the text matched an the confidence score. You can also click on the JSON tab to see the raw data returned by the REST API.
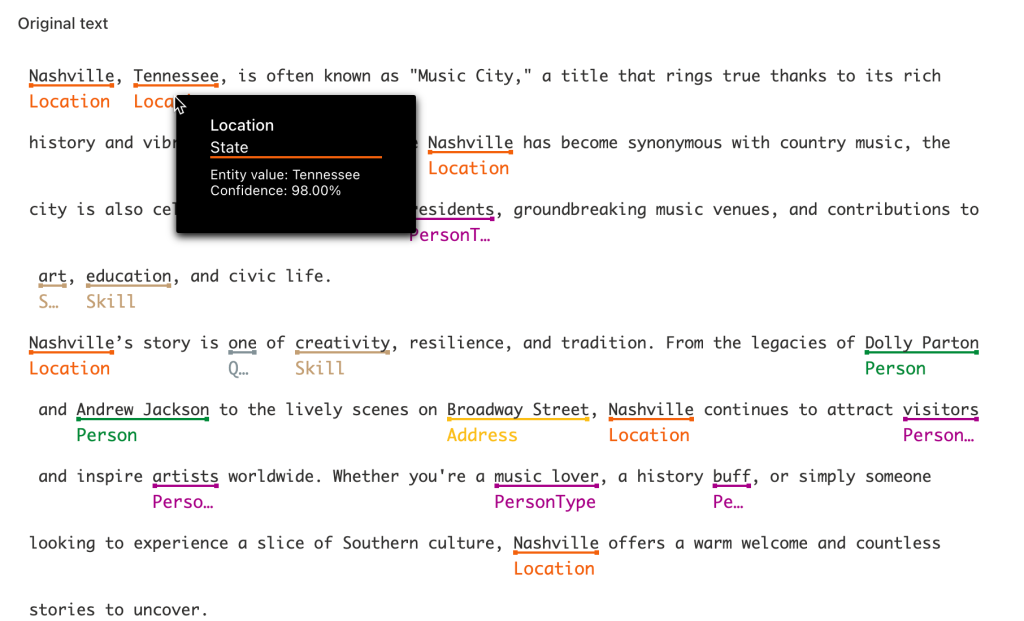
The other view is the original text of the document. However, it is annotated with a link for each entity. Hovering over the entity will show the card with additional information such as the category.
Summary
In this post you saw how to use the named entity recognition feature (NER) of the Azure AI Language Service. You learned how to use the Python SDK to get details of the entity. The SDK provides methods to extract named entities for both a generalized model and a domain specific model for health care. The Azure Language Studio provides access to entity recognition and the other features of the Azure AI Language Service in the browser.